一、JML语言梳理
1.理论基础
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言,结合了Eiffel的契约方法设计和Larch系列接口规范语言的基于模型的规范方法,以及细化演算的一些元素。它以标准化的语言描述了类与方法的属性和规格,便于代码工作人员理解和实现。JML主要由Leavens教授在Larch上的工作,并融入了Betrand Meyer, John Guttag等人关于Design by Contract的研究成果。JML是一种规约性语言,很好的实现了设计与实现的分离,为严格的程序设计提供了一套行之有效的方法,也保证了实现的高效性和多人合作时的可交互性。
一般而言,JML有两种主要的用法:
①开展规格化设计。这样交给代码实现人员的将不是可能带有内在模糊性的自然语言描述,而是逻辑严格的规格。
②针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性。这在遗留代码的维护方面具有特别重要的意义。
2.应用工具链
①SMT Solver:检查代码是否满足规格
②openJML:检查规格规范性
③JMLUnitNG:实现自动测试
二、OpenJML与JMLUnitNG的部署和使用
1.下载OpenJML(带有不同平台下的SMT Solver)和JMLUnitNG
2.使用IDEA中的ExternalTools配置OpenJML和JMLUnitNG,代替Windows命令行的使用(参考IDEA配置OpenJML教程)
3.使用JMLUnitNG自动生成测试数据和相关文件,在这里只是对一个简单的compare方法进行了验证。

4.对测试类Demo_JML_Test进行OpenJML运行时动态检查(ExtrenalTools配置命令行)可得自动化测试结果
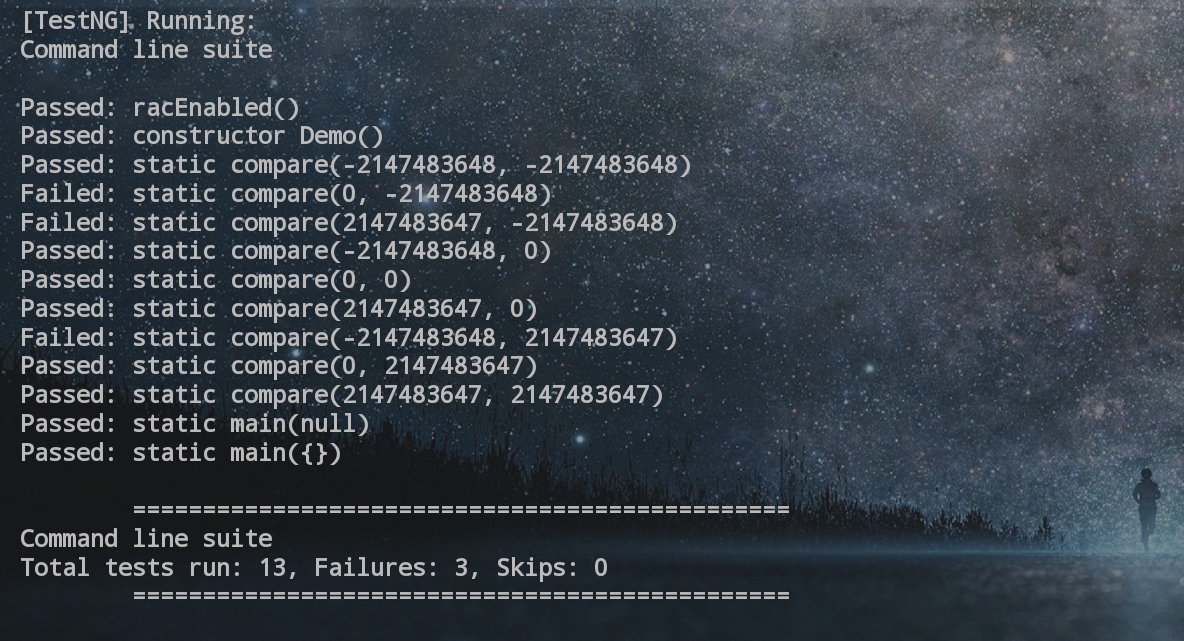
可以发现测试用例均为边界样例,包括0和int类型的最大值和最小值以及空指针null,这样的数据优点是能帮我们排查边界条件的错误(比如在本单元第一次作业中许多同学都使用了本代码中的compare方法去完善compareTo接口,最终导致了溢出bug,这样的边界测试是可以及时发现这种错误的,在上面的测试结果中也可以看到溢出点全部为failed),但从测试功能的全面性角度来讲,这样的样例测试显然是不够完备的。
三、历次作业分析
第一次作业
1.架构分析
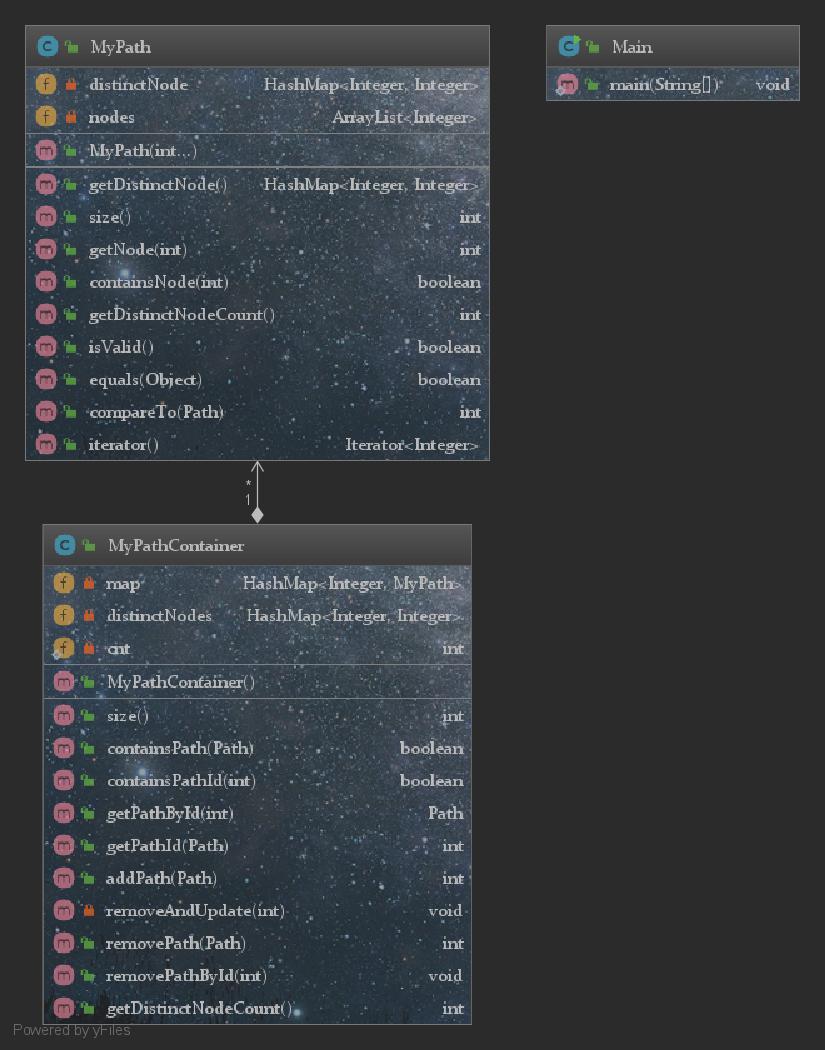
由于官方封装了接口并给定了所要求实现的类的规格,所以第一次作业并没有太多需要自己进行架构的地方,只需要按照规格一个个地实现方法需求即可。在保证了功能正确性后,再在程序执行效率上进行优化,考虑到查询指令的数量是要远大于增删指令的,故需要做到查询时的复杂度为O(1),把需要循环遍历的预处理过程分散到本就不能够降低复杂度的增删指令中去,这就需要新的数据结构来存储预处理得到的结果。HashMap具有良好的增删查属性,在PathContainer中使用HashMap来存储Path,可以实现路径查询时的低复杂度,同时我为两个类都增加了名为distinctNode的HashMap结构,key和value分别为nodeId和该node的出现次数,这样在增删Path的时候同时完成distinctNode结构的维护,如果该Node出现次数归零则从HashMap中删除,从而保证了两条查询指令DISTINCT_NODE和PATH_DISTINCT_NODE都是O(1)复杂度,无需再进行循环遍历,从而降低了时间复杂度。
2.Bug分析及修复
这一次作业中被测出一个bug,主要由于在添加路径操作时对PathContainer类的distinctNode的更新写错了,本来PathContainer的distinctNode的value应该为key值对应的node出现在不同路径中的次数(即在一条路径中一个结点只会出现一次或零次),但是我却把结点所有重复出现的次数都统计了进来,而在删除路径时,我却只会将路径所包含结点的出现次数减一,从而导致了很多本应该删去的结点留在了distinctNode中。这一次的Bug是比较愚蠢的,如果在编写代码过程中对于自己各项结构的含义以及每条语句想要实现的功能足够明确,这种错误是不会出现的,同时也反映出了自己对程序的测试不够全面,没能够及时发现错误。
第二次作业
1.架构分析
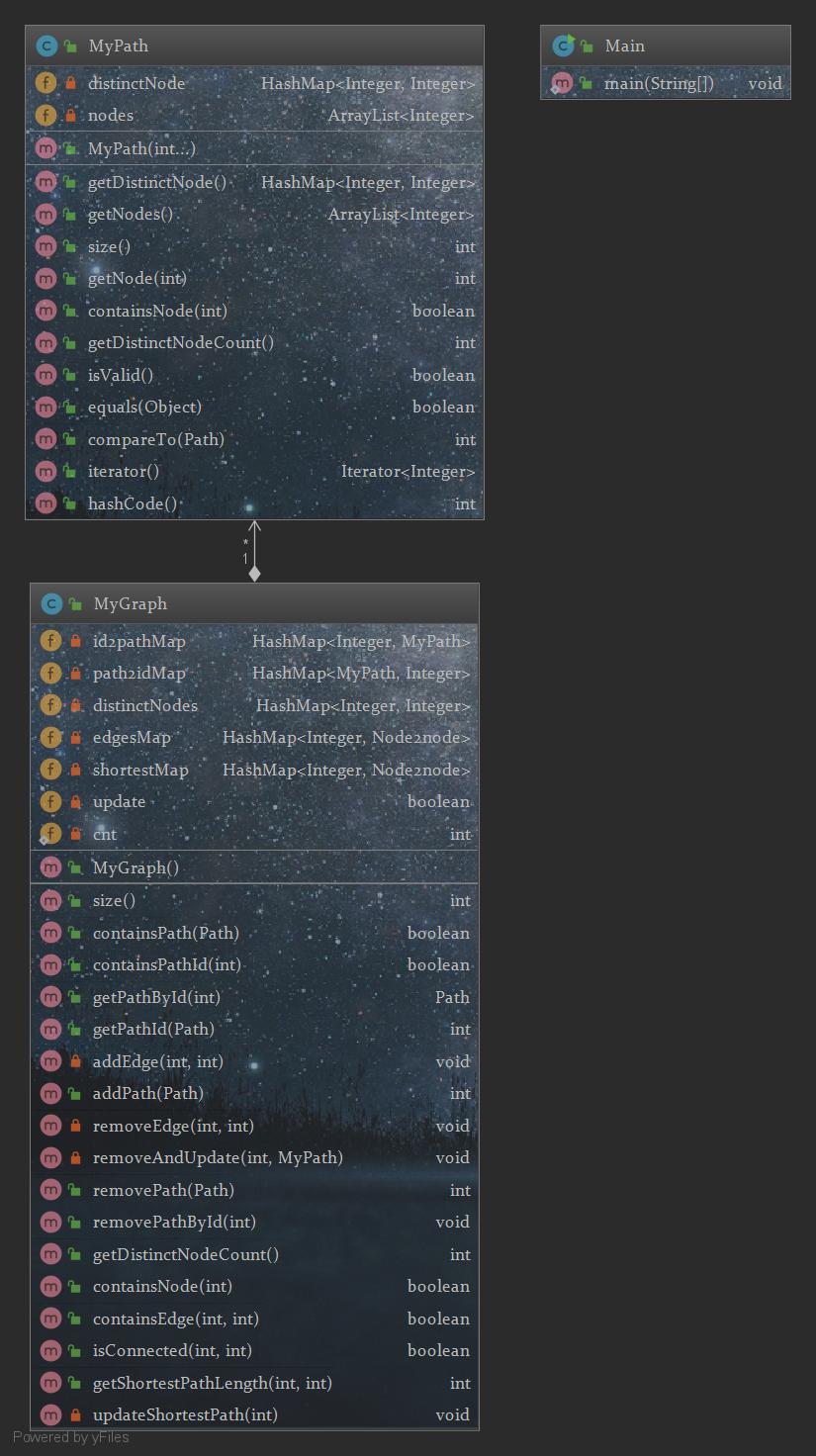
第二次作业在上一次的基础上将PathContainer类扩展成了图结构,并添加了与图相关的一些指令。在架构上我也是继承了上一次的全部设计(并将存储Path的单HashMap扩展为两个,通过重写MyPath类的hashCode方法,实现了Path->Id和Id->Path的双向O(1)查询)以保证之前的指令全部满足,并在此基础上进行进一步的扩展。图概念的引入打破了Path之间的相互独立性,每个结点之间的连通性成为判断isconnected和求解shortestPathLength的关键,于是引入新的HashMap结构edgesMap用来存储点与点之间的边,为了充分利用HashMap增删查的高效性,将edgesMap设计成HashMap嵌套的形式,即HashMap<Integer,HashMap<Integer,Integer>>,在这里的三个Integer中,前两个为结点Id,最后一个为这两个结点之间边在所有Path中出现的次数(删除一个包含edge的Path后两个结点依旧可能有边相连)。这样对于一对结点来说,如果以其中一个的Id为key在edgesMap中对应的HashMap的Keyset中如果不含另一个结点的Id,则这一对结点之间无边即不相连,可以实现对于任意边的O(1)查询,从而保证了时间效率。对于最短路径的查询,先预处理出结果存储在shortestMap结构中,shortestMap结构的具体实现思路与edgesMap相同,也是一个嵌套结构,只不过最后一个Integer存储的是两个结点之间的最短路径长度,也可以实现O(1)查询,由于查询次数远多于图结构改变的次数,所以增加update用来记录图结构是否发生改变,只有在改变时才会计算新的shortestMap。在增删路径时需要对edgesMap进行维护,对于路径中的每一对相邻结点都进行边的增删,只有增加或减少新的边(而非在原有边的基础上增减次数)时才将update置为true,从而整个程序处于最高效率状态。
2.Bug分析及修复
这一次的作业在强测和互测中都没有被发现bug。
第三次作业
1.架构分析

第三次作业在上一次的基础上将Graph扩展为RailWaySystem,增加了更贴近实际需求的几条指令。首先是连通块数量的查询,由于上一次的作业中isconnected的判断是根据最短路的计算结果,故在本次作业中无法再次使用,只能采取新的算法,于是我用了一个类似并查集的算法,使用connectedMap结构记录每个节点所属的块,在判断isconnected时只判断两个结点在connectedMap中对应的value是否相同即可,而关于connectedMap的维护和更新则是单独写了一个updateConnectedNodes方法,使用BFS循环所有节点,队空次数即为连通块数量,使用blocks进行记录,队空之前入队的所有结点在connectedMap中的value值均更新为第一个队首结点的值,同时update记录图结构的变化,只有为true时才会调用该方法进行更新。而对于新增的路径查询指令,由于换乘代价的引入,导致最短路的最优子结构被破坏,不能直接在原图上使用最短路算法,需要对图结构进行处理保证最短路算法仍能执行得到正确结果。图的预处理方法有两种,一是拆点法,二是路径内部连最短边法。我在本次作业中采取的是第二种方法,可以发现四种路径需求指令的本质结构是一样的,都涉及到换乘代价和边的权重,即对于最短路径边权为1,换乘代价为0;最少换乘边权为0,换乘代价为1;最低票价边权为1,换乘代价为2;最小不满意度边权为u(v1,v2),换乘代价为32。除了权值不同,这四类图的建图和维护都是相同的,于是在此引入一个新的类BuildGraph来封装这些操作,对于边的存储则沿用上一次作业中的方法,使用HashMap嵌套结构来保证O(1)的查询复杂度,同时边的信息也不再只有出现次数简单的一项,因此加入EdgeInfo项记录边的信息,该类中的HashMap<Integer,int[]>中的Integer为包含该边的Path的Id,int[]保存了四种权值分别用于四种指令的计算,这样存储的原因为边的权值在使用最短路算法时必须是唯一的且是最小的,而不同的Path可能会给相同的边赋上不同的权值,而且随着Path的增删,最小权值在不断发生变化,所以必须将PathId与权值对应明确,才能保证增删路径时边的权值得到正确的更新。在添加Path的时候,需要在Path内部先进行一次最短路计算,得到Path内部各结点间的最短路,并为每个节点间添加相应权值的边;在计算最短路结果时,初始化answerMap将每个结点间的边最小权值加上换乘代价得到最终权值,并进行最短路计算得到的结果再减去一次换乘代价即为最终结果。由于这里涉及到两次最短路的计算,故将其封装成名为floyd的方法供addPathMap和updateAnswer方法调用,同时对于不同的最短路指令,需要输入相应的index编号,保证updateAnswer内调用floyd时使用正确的weight [index]进行计算。使用update[]数组来记录每个图结果的更新情况,而不是一次性更新四个图的结果,省去了多余的计算过程,提高了时间效率。
2.Bug分析及修复
这一次的作业在强测中被发现一个bug,主要由于本次作业需要对图结构进行更改才能保证最短路算法的正确应用,而我却没有记录更改之前的原图结构,因为在我采用的算法中会将同一个Path内的所有结点全部连边,而原图结构之中只有Path内的相邻结点才会有edge相连,从而导致CONTAINS_EDGE指令出错。只要在原来的基础上增加一个realMap结构记录原图结构,并采用第二次作业的方法进行维护和查询即可。
四、心得体会
本单元的主要内容为规格化设计,并介绍了JML语言来描述规格。规格的使用能够更好地实现设计与实现的高度分离,当我们进行架构设计时只需考虑类和方法想要实现的功能和最终得到的结果,而不去关心具体的实现细节。同时,规格作为一种纲领式的编码要求,统一明确且全面地写出了前置条件、后置条件、结果、异常等,使模块化的自动测试成为了可能。总的来说,规格是不同代码实现风格上的又一层封装,统一且逻辑严谨地对代码行为进行规范,让代码的交流和维护有理可依且更加方便。
虽然在本单元的作业中,规格都已完成好且整体架构都已经实现了封装,我们只是根据规格来实现自己的代码,而并不需要自己来撰写规格,但是我知道在将来的工作学习中,还是会遇到整个从零开始的大型项目的,这时候规格的使用就变得十分重要,好的规格设计能够大幅减少重构的概率且有利于团队之间的交流和对代码的共同维护,本单元所学习到的规格化设计思想是面向对象编程的重要内容,短短三周的学习只是初探皮毛,未来还有更长更远的路要走,加油!